人工智能(AI)是当今科技领域的热门话题,而神经网络则是其核心技术之一。对于初学者来说,神经网络听起来可能很复杂,但实际上,它的基本思想可以用简单的方式来理解。本文将以最通俗的语言,带你入门神经网络的基础知识,并简要介绍其在软件开发中的应用。
一、神经网络是什么?
想象一下,你正在学习识别猫和狗。一开始,你可能通过观察它们的耳朵、尾巴和体型来区分。神经网络的工作原理类似:它由许多“神经元”组成,这些神经元相互连接,共同处理信息。每个神经元接收输入信号,经过计算后输出结果,就像大脑中的神经细胞一样。神经网络通过大量数据训练自己,逐渐学会识别模式,比如区分猫和狗的图像。
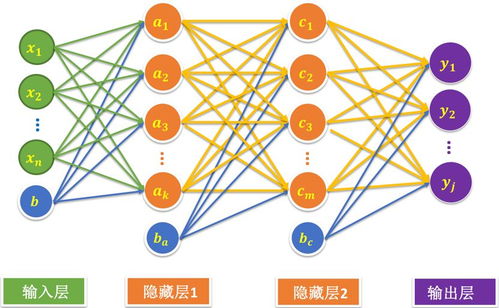
二、神经网络的基本结构:
- 输入层:这是神经网络接收数据的地方。例如,如果你要处理一张图片,输入层会接收像素值。
- 隐藏层:这是神经网络的核心部分,负责处理输入数据。隐藏层可以有多层,每层包含多个神经元,它们通过计算提取数据的特征。
- 输出层:这是神经网络给出结果的地方。例如,在猫狗识别任务中,输出层可能会输出“猫”或“狗”的概率。
三、神经网络如何学习?
神经网络的学习过程类似于试错。它通过“训练”来调整神经元之间的连接强度(称为权重)。训练时,神经网络会接收大量带标签的数据(比如标注为“猫”或“狗”的图片),并尝试预测结果。如果预测错误,它会自动调整权重,以减少错误。这个过程反复进行,直到神经网络能够准确识别模式。
四、神经网络在软件开发中的应用:
作为人工智能的基础,神经网络已广泛应用于软件开发中。以下是一些常见应用场景:
- 图像识别:例如,手机相册自动分类照片,或安防系统识别人脸。
- 自然语言处理:例如,智能客服聊天机器人,或翻译软件。
- 推荐系统:例如,电商平台根据你的浏览历史推荐商品。
- 自动驾驶:神经网络帮助汽车识别道路、行人和障碍物。
对于软件开发人员来说,入门神经网络并不难。现在有许多开源工具和框架,如TensorFlow和PyTorch,提供了简单易用的接口,帮助开发者快速构建和训练神经网络模型。即使没有深厚的数学背景,你也可以通过实践来掌握基础知识。
五、入门建议:
- 学习基础知识:了解神经网络的基本概念,如神经元、权重和激活函数。
- 动手实践:使用Python等编程语言,结合TensorFlow等框架,尝试构建简单的神经网络模型(比如手写数字识别)。
- 参考在线资源:网上有许多免费教程和课程,如Coursera或YouTube上的教学视频。
神经网络是人工智能的重要组成部分,它以模拟人脑的方式处理信息,广泛应用于各种软件中。通过通俗的理解和实践,任何人都可以入门这一领域,为未来的科技发展贡献力量。希望这篇文章能帮助你迈出神经网络学习的第一步!